
Deutschland
Palantir-Dossier: IT der Sicherheitsbehörden – US-Anbieter auf dem Vormarsch – Teil 5
Die hessische Polizei hat bei der US-Firma Palantir die Einrichtung und den Betrieb der Analyseplattform "Hessendata" gekauft. Offizielle Informationen dazu sind rar. Ein Bild der Funktionsweise des Systems ergibt sich aus anderen öffentlich verfügbaren Quellen.

Das Portal Police-IT widmet sich ausführlich dem Themenkomplex Polizei und Informationssysteme, der für jede und jeden relevant ist, da es uns alle jederzeit und unmittelbar betreffen kann. Mit freundlicher Genehmigung der Herausgeberin und langjährigen Expertin für polizeiliche Informationssysteme, Annette Brückner, veröffentlicht RT Deutsch Teile des auf Police-IT erschienenen Dossiers zu Palantir.
Alle auf RT Deutsch erschienenen Teile des Palantir-Dossiers finden Sie hier.
Vorbemerkung der Redaktion: Dieser Teil des Palantir-Dossiers behandelt mit der Funktionsweise die technische Seite der polizeilichen Analyseplattform "Hessendata". Diese Beschreibung technischer Details bietet dafür einen konkreten Einblick in grundlegende Probleme und Gefahren beim praktischen Einsatz und Betrieb eines solchen datenbasierten Analysesystems.
Teil V – Palantir Gotham alias Hessendata: System und Funktionsweise
Es gibt viele Fragen über die "Analyseplattform", die sich die hessische Polizei bei der Firma Palantir gekauft hat und deren Betrieb sie in die Hände dieser Firma gelegt hat. Antworten sucht man allerdings vergeblich: Das hessische Polizeipräsidium für Technik als Auftraggeber hält sich extrem bedeckt. Aus dem Innenministerium hört man noch weniger. Denn die Opposition hatte noch vor der Landtagswahl einen Untersuchungsausschuss durchgesetzt: Doch der kümmert sich ohnehin nur um die sehr freihändige, zweimalige Auftragsvergabe an Palantir (siehe Teil II, Teil III und Teil IV). Das hessische Innenministerium hat bisher trotz mehrfacher Nachfrage keine unserer Presseanfragen zu Palantir beantwortet. Und Fragen an die Firma Palantir selbst? Deren CEO Alex Karp pflegt das Image von Palantir als dem "geheimnisvollsten Unternehmen der Welt". Eine Telefonnummer ist auf der US-amerikanischen Webseite nicht zu finden. Presseanfragen können nur per E-Mail im Silicon Valley eingereicht werden. Darauf haben wir verzichtet.
Stattdessen haben wir uns durch eine Fülle von öffentlich verfügbaren Dokumenten über Palantir und deren Produkt Gotham gearbeitet. Woraus bekanntlich "Hessendata" geworden ist, die neue Analyseplattform der hessischen Polizei. Da wäre zunächst, was die Firma selbst dazu sagt: Denn sie macht Werbung, wenn auch zurückhaltend. Und sie bedient die Medien in den USA und Europa mit Erfolgsgeschichten über ihre Produkte. Daneben gibt es technische Kommentatoren, die sich mit Palantir beschäftigen. Und öffentliche Äußerungen von Mitarbeitern von Palantir-Kunden. Alle diese Quellen liefern Einzelinformationen, aus denen sich ein Bild ableiten ließ, wie Palantir Gotham alias Hessendata eigentlich funktioniert.
Nehmen Sie den vorliegenden Teil V des Palantir-Dossiers von POLICE-IT als eine Kurzbeschreibung des Systems und seiner Funktionsweise, so wie ich sie aus diesen Quellen und aufgrund meines technischen Hintergrunds* verstehe.
Das Kardinalproblem der polizeilichen Informationsverarbeitung
Die Polizei hat im Zusammenhang mit ihrer Informationsverarbeitung zwei Kardinalprobleme.
- Die Polizei selbst hat – eigentlich – eine Unmenge von Informationen.
Doch diese Informationen sind verstreut gespeichert: Im Vorgangsbearbeitungssystem, dem Fallbearbeitungssystem, in Datenbanken für bestimmte Deliktsbereiche, Meldediensten, dem Asservatenverwaltungssystem der Kriminaltechnik, in den innerpolizeilichen Fernschreiben usw. Trotz großer Anstrengungen ist es bisher weder einer einzelnen Polizeibehörde noch behördenübergreifend auch nur ansatzweise gelungen, einen zentralen Datenpool zur Verfügung zu stellen, der alle relevanten Informationen enthält. - Es fehlt am Blick auf das große Ganze:
Obwohl die Informationen "eigentlich" und "irgendwo" vorhanden sind, können sie nicht genutzt werden. Was sich die Polizei und die Innenpolitiker dringend wünschen, wurde vielfach formuliert in markigen Sprüchen: Seit über einem Jahrzehnt wiederholt die Führungsspitze im Bundeskriminalamt (BKA) ihr Mantra, man müsse "Tat-Tat- und Tat-Täter-Zusammenhänge erkennen" können. Oder auch "vor die Lage kommen", was heißen soll, dass Straftaten verhindert werden sollten, bevor sie überhaupt begangen werden. Beides setzt voraus, dass die Polizei eine Art "Röntgenblick" erhält auf die "eigentlich" vorhandenen Informationen. Das wäre viel leichter, wenn wichtige Datenquellen auf einer einheitlichen Plattform zusammengeführt würden.

Palantir Gotham – Eine kurze Beschreibung des Systems und seiner Funktionsweise
Palantir Gotham alias Hessendata verspricht eine Lösung für dieses Problem. In einer Systembeschreibung von Palantir heißt es dazu:
Behörden haben Daten. Eine ganze Menge davon. Strukturierte Daten, wie Protokolldateien, [Excel-]Arbeitsblätter und Tabellen. Unstrukturierte Daten, wie E-Mails, Dokumente, Bilder und Videos. Solche Daten werden typischerweise auf unterschiedlichen Systemen gespeichert. Sie unterscheiden sich ganz erheblich voneinander, das Datenvolumen wächst über die Maßen schnell an und es wird von Tag zu Tag schwieriger, damit umzugehen.
Menschen allerdings, die auf diese Daten angewiesen sind, denken nicht in Kategorien wie Datensätze oder Spalten oder Rohtext. Sie haben die Aufgabe ihrer Behörde im Blick und die aktuellen Herausforderungen, mit denen diese konfrontiert ist. Die Menschen brauchen Wege, Fragen an ihre Daten zu stellen und Antworten in einer Sprache zu bekommen, die sie auch verstehen.
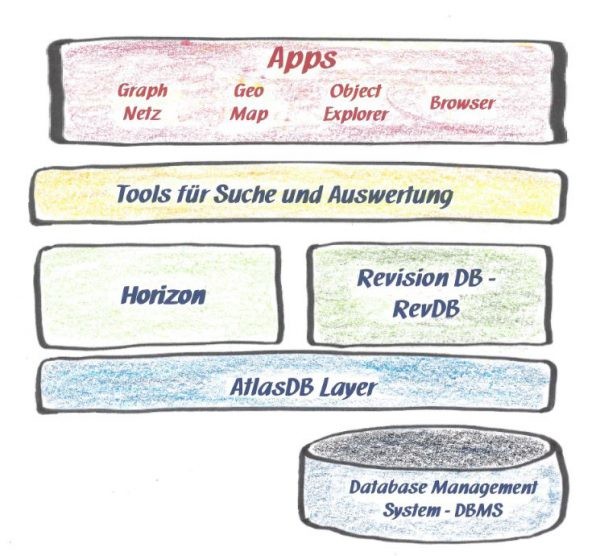
Die Systemkomponenten von Palantir Gotham
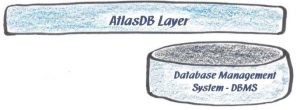
Natürlich arbeitet ganz unten, im Maschinenraum von Gotham, auch ein Datenbanksystem. Für den Zugriff darauf gibt es "AtlasDB": Das ist ein systeminterner, skalierbarer Schnittstellen-Layer, der einheitliche DB-Zugriffsfunktionen zur Verfügung stellt, unabhängig davon, welches DB-System ganz unten verwendet wird.
Die eigentliche Analyseplattform
Die eigentliche Analyseplattform besteht aus zwei Komponenten:
- einer InMemory-Datenbank namens Horizon, auf der die Analytiker ihre Auswertungen durchführen und
- der Revisioning DB (RevDB) für das Speichern der Informationen aus den verschiedenen Quellsystemen.

Palantir sagt darüber:
Die Revisioning Database oder RevDB ist der Speicher zum dauerhaften Speichern in Palantir Gotham. Zu allen Informationselementen in der RevDB werden zusätzliche Informationen darüber gespeichert, wann sie erstellt oder modifiziert wurden, über den Nutzer, der sie erstellt oder verändert hat, über die Datenquelle, aus der sie ursprünglich gewonnenen wurden und etwaige Sicherheits- oder Zugriffsbeschränkungen.
Und an anderer Stelle heißt es:
Die RevDB verfolgt alle Veränderungen an einem Objekt, egal ob diese in der Datenquelle vorgenommen wurden oder von Nutzern des Palantir-Systems. Der Analytiker kann damit in seinem eigenen "Sandkasten" Hypothesen in verschiedenen Versionen ausarbeiten und verfeinern, verschiedene Stränge für Kausalitäten oder die Beweisführung verfolgen und jederzeit auch wieder zurück gehen auf eine frühere Version der Auswertung.
Das Ergebnis ist eine Plattform über das angesammelte Wissen und die Hypothesen der Nutzer, wodurch deren Analysen in Informationen verwandelt werden, die von der Organisation zu deren Vorteil eingesetzt werden können [wörtlich: 'turning their analyses into data that can be further leveraged by the enterprise'].
Tools für Suche und Auswertung
Zwischen den Datenspeichern und den Anwendungen, mit denen die Nutzer arbeiten, wirken im Hintergrund und ohne dass der Nutzer davon viel mitbekommt Systemdienste mit so klangvollen Namen wie "Raptor" (zu deutsch: Raubvogel), "Phoenix" (noch ein Vogel, diesmal aus der Asche) oder einfach "Search". Aufhorchen lässt die knappe Beschreibung** von "Raptor", einem Dienst der "on-the-fly" federated searches auf externen Datenquellen ausführt. Das legt folgende Arbeitsweise nahe: Ein Auswerter interessiert sich für eine Person X. "Raptor" muss dann vermutlich aktiviert werden und würde in diesem Moment alle (vermutlich definierten) anderen, externen Datenquellen nach dieser Person X durchsuchen. Treffer in diesen Datenbanken werden dann – sagt Palantir – in die Revisioning DB übernommen und dort gespeichert. Sehr spannend finde ich in diesem Zusammenhang die Frage, welche "externen Datenquellen" in Hessendata für den Dienst "Raptor" zur Verfügung stehen. Und ob dazu auch Abfragen in sozialen Medien, wie Facebook, Twitter & Co, gehören!
Die Apps = Anwendungen
Die Anwendungen stellen die "Schnittstelle" dar, mit der die Nutzer mit der Analyseplattform kommunizieren, dort Eingaben machen oder Auswertungen durchführen.
Dazu gehört "Graph", zur Darstellung von Beziehungsnetzen, "Geo" für die Darstellung und Anzeige auf Karten, ein "Object Explorer" und ein "Browser". Ich gehe ganz bewusst nicht näher auf diese Anwendungen ein. Erstens können Sie selbst leicht entsprechende Bildschirmfotos im Internet finden. Zweitens ist an diesen Anwendungen nichts so richtig neu. Schon lange vorher gab es und gibt es immer noch Analyst's Notebook und verwandte Produkte von IBM. POLYGON kann auch schon sehr lange "graph", also die Darstellung von miteinander vernetzten Objekten "on-the-fly". Und der "Object Explorer" liefert offensichtlich eine Art Dossier über eine Person, mit allen relevanten Informationen und Dokumenten, die ein Auswerter in diesem Dossier mal zusammengeführt hat. So etwas nannte man schon zu DDR-Zeiten ein "Personagramm" und auch das ist in aktuell verwendeten Fallbearbeitungssystemen längst Standard …
Was die Apps von Gotham für die Nutzer attraktiv machen dürfte, ist die Mischung aus Komfort, Einfachheit in der Bedienung, Schick und vermutlich auch ein Anteil von "Spaß und Spiel". Denn solche modernen "Apps" machen dem Nutzer natürlich mehr Spaß als die altbackene, dröge Benutzeroberfläche der bisher genutzten polizeilichen Informationssysteme, die vor fünfzehn bis zwanzig Jahren entwickelt wurde. Mit den Apps von Gotham/Hessendata kann man auf einer grafischen Oberfläche mit Daten "herumspielen", mal eine Idee ausprobieren und sich – "zeig mal, wohin diese Beziehung im grafischen Netzwerk führt" – zeigen lassen, wohin diese führt. Für einen Auswerter ist ein solches Werkzeug eine willkommene – und sinnvolle! – Unterstützung zur Aktivierung der eigenen Kreativität und Unterstützung der Hypothesenbildung. Gefährlich wird es, wenn solche "Gedankengänge" von der Analyseplattform Horizon zurückgespeichert werden: in den permanenten Speicher der Revisioning DB. Ich sehe darin die Gefahr, dass solche Gedankenspiele, also Hypothesen des Analytikers, von echten, bewiesenen Fakten nicht mehr deutlich genug unterschieden werden können, und polizeiliche bzw. strafrechtliche Entscheidungen zunehmend mehr auf Annahmen als auf Fakten basieren.
Für Hessendata muss die Zukunft zeigen, ob eine für den Nutzer und Betrachter attraktive Benutzeroberfläche und die Präsentation von "Erkenntnissen" in vielen schönen Bildern wirklich mehr bringt: Letztlich geht es für eine verantwortungsvoll agierende Polizei um belastbare Erkenntnisse, die die Basis bilden für anschließende Entscheidungen. Ist Palantir wirklich in der Lage, eine alte Faustregel auszuhebeln, die besagt, dass Erfolg zu 95 Prozent auf Transpiration beruht und zu 5 Prozent auf Inspiration?
Es wäre zu hoffen, dass diese Frage OBJEKTIV untersucht und beantwortet wird. Und nicht allein von frühen Adepten der Firma aus dem hessischen Innenministerium, die einen Erfolg brauchen – nach ihrem sturen, letztlich aber gescheiterten Festhalten an der hessisch-hamburgischen Eigenentwicklung CRIME. Und auch nicht von Anwendern in einem Polizeipräsidium, denen das Innenministerium die Chance gegeben hat, mehr Primus zu sein, als das Landeskriminalamt (LKA) des Landes.

Die flexible Speicherstruktur
Weitaus mehr als die schicken Apps von Palantir steckt die Leistungsfähigkeit dieses Systems tief unter der Motorhaube – und zwar insbesondere in seinem Daten- und Informationsmodel. Palantir sagt selbst:
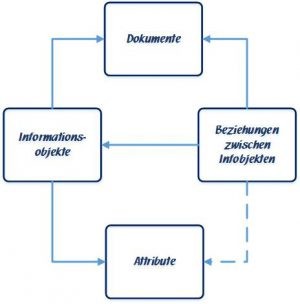
In Gotham werden Informationen als Graphen behandelt, an deren jeweils einem Ende ein Informationsobjekt sitzt, das mit dem anderen durch eine (benannte) Beziehung verbunden ist. Diese Informationsobjekte sind Repräsentanten für Objekte aus der realen Welt, wie Menschen, Unternehmen, Sachen, Orte der Ereignisse usw. Sie werden mit Attributen näher beschrieben oder identifiziert (Namen, KFZ-Kennzeichen, Telefonnummer) und können mit Beziehungen miteinander verknüpft werden.
Die verwendete Speicherstruktur in Palantir Gotham ist im Kern nicht neu. Sie ähnelt im Prinzip der so genannten EAV/CR-Struktur bzw. dem generischen Datenmodell, wie es in der Polygon-Patentschrift beschrieben und in POLYGON realisiert und als Variante davon im Fallbearbeitungssystem CRIME (eingesetzt u. a. in Hessen) und in INPOL-Fall (eingesetzt beim BKA als Plattform für kriminalpolizeiliche Meldedienste) verwendet wird.
Für den Beobachter bleibt ein ironisches Schmunzeln nicht aus: Denn Hessen braucht dringend einen Nachfolger für CRIME und beschafft sich mit Palantir Gotham alias Hessendata nun ein neues System mit einer sehr ähnlichen Speicherstruktur wie die von CRIME. Ob sich die Entscheider im hessischen Innenministerium und Landespolizeipräsidium darüber klar sind? Und ob sie haben prüfen lassen, welche Fehler, die zum Aus von CRIME führten (und die nichts mit dessen Datenmodell zu tun hatten!), beim Einsatz von Palantir tunlichst zu vermeiden sind?
Vier wesentliche Strukturelemente
- Das gemeinsame Merkmal der oben genannten Speicherstrukturen ist ihre Objekt-Orientiertheit. Jede Einzel-Information bezieht sich auf ein Informationsobjekt, wie z. B. Personen, Orte, Sachen, Ereignisse usw. Für jedes Objekt, das im Ausgangs-Datenmaterial erkannt wird, wird in der Datenbank ein Informationsobjekt gebildet.
- Alle Details, die ein Objekt näher beschreiben oder auch identifizieren, werden diesem Informationsobjekt in der Datenbank als Attribute / Merkmale / Features (jeder nennt es anders ...) zugeordnet.
- Eine Beziehung verknüpft jeweils ein Informationsobjekt mit einem zweiten und macht eine Aussage über die Art der Beziehung (Geschäftsführer, Mieter, Fahrzeughalter usw.).
- Und dann gibt es in der Datenbank noch (mindestens) einen Speicherbereich zum Speichern von Dokumenten, Bildern, Tonmitschnitten und Videos.
Die Speicherbereiche
Für jedes dieser vier Strukturelemente gibt es einen eigenen Speicherbereich, nämlich
- einen Speicherbereich für sämtliche Informationsobjekte, egal ob es sich um Personen, Orte, Sachen, Ereignisse oder sonst was handelt: Darin wird mindestens eine Bezeichnung für das Objekt gespeichert sowie der Objekttyp, der besagt, ob es sich um eine Person, einen Ort, eine Sache oder ein Ereignis usw. handelt. Anders als in konventionell modellierten Datenbanken, werden in diesem Speicherbereich für die Informationsobjekte jedoch keine Attribute gespeichert!
- einen Speicherbereich für sämtliche Attribute zu allen Objekten: Darin wird für jedes Attribut ein Attributbegriff gespeichert sowie die dazugehörende Attributbedeutung.
- einen Speicherbereich für sämtliche Beziehungen. Darin wird für jede Beziehung ein Verweis auf das erste und auf das zweite Objekt gespeichert und zusätzlich eine Aussage über die Beziehung.
- einen oder mehrere Speicherbereiche für die Dokumente, Bilder etc.: Darin wird der elektronische Inhalt des Dokuments, Bildes, der Audio-oder Videosequenz gespeichert.
Die Zuordnung von Attributen zu dem Informationsobjekt, das sie näher beschreiben oder identifizieren, ist in den o. g. Speicherstrukturen auf unterschiedliche Weise gelöst: Der Verweis auf das zugehörige Objekt kann im gleichen Speicherbereich wie das Attributpärchen gespeichert sein. Oder es gibt einen eigenen Speicherbereich, der einen Verweis auf das Attributpärchen (Haarfarbe: braun) und einen weiteren Verweis auf das zugehörige Objekt enthält.
Und zusätzlich gibt es in jedem dieser Speicherbereiche für jedes einzelne Element einen eigenen Schlüssel (Key), der für die Referenzierung und Verwaltung innerhalb des Systems benötigt wird.
Logisches Informationsmodell
Allerdings wirft diese Speicherstruktur ein Problem auf: Denn es gibt jetzt ja nur noch EINEN Speicherbereich, in dem SÄMTLICHE Informationsobjekte zumindest mit ihrem Namen gespeichert werden. Damit man aber Personen von Orten und Sachen von Ereignissen usw. unterscheiden kann, muss zusätzlich ein Objekttyp angegeben werden. ObjektTYPEN dienen also dazu, gleichartige Informationsobjekte, wie Personen, Orte, Sachen und Ereignisse etc., zu Gruppen zusammen zu fassen und innerhalb der Gruppe miteinander vergleichbar zu machen.
Ganz ähnlich sieht es bei den Attributen aus: Auch dort wird ein AttributTYP benötigt, denn der AttributBEGRIFF alleine würde ja keine Aussagekraft haben: Stellen Sie sich zum Beispiel ein Datum vor, wie "06.11.2012". Alleinstehend kann man überhaupt nicht sagen, was dieses Datum für eine Bedeutung hat. Erst durch die zugefügte Attributbedeutung weiß man, dass es sich um ein Geburtsdatum handelt oder um das Datum, zu dem ein Versicherungsvertrag abgeschlossen worden oder ein Unfall geschehen ist.
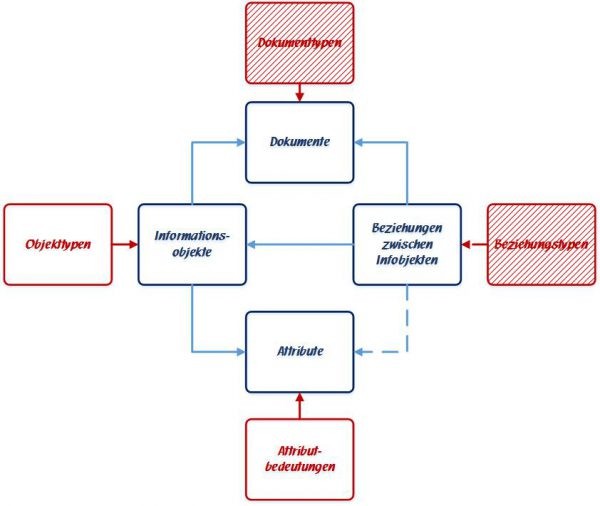
Speichermodelle wie EAV/CR, POLYGON und ähnliche Varianten wie CRIME bzw. INPOL-Fall speichern die Typ-Informationen beim jeweiligen Objekt oder Attributbegriff usw. explizit mit. Demzufolge braucht es in diesem Datenmodell eine Möglichkeit, um die im System zulässigen und bekannten Objekttypen, Attributbedeutungen usw. EINMAL zu definieren und zu hinterlegen. Allgemein nennt man einen solchen Vorrat der Typ-Informationen für Informationsobjekte, Attribute, aber auch für Beziehungen und Dokumente, ein "logisches Informationsmodell".
Das logische Informationsmodell von Palantir, die "dynamische Ontologie"
Palantir bezeichnet sein Datenmodell und das logische Informationsmodell darin als "dynamische Ontologie" [Der Begriff Ontologie wird mitunter als Synonym für "logisches Informationsmodell" verwendet]. Und dynamisch ist dieses Informationsmodell insofern, als es frei definiert und auch erweitert werden kann. Ohne dass deswegen die eigentliche Speicherstruktur, also das physische Datenmodell angelangt werden muss.
Beim Verfasser der Palantir-Datenblätter geht es ein wenig hin und her mit den Begriffen: Denn das "objektbasierte Datenmodell" ist die eine Sache – wir hatten sie oben korrekt als das physische Speichermodell beschrieben. Und das logische Informationsmodell ist die zweite Sache. Sie heißt bei Palantir die dynamische Ontologie.
Aus beidem zusammen wird ein funktionierendes Ganzes:
Das flexible, vereinheitlichte Datenmodell in Palantir Gotham vereinfacht den Prozess der Datenintegration ganz ungemein. Und die dynamische Ontologie in Palantir Gotham erlaubt es, Informationen aus ganz unterschiedlichen Quellsystemen und Speicherformaten in Informationsobjekte und zugehörige Attribute zu verwandeln, die Objekte aus der realen Welt und die Beziehungen zwischen diesen Objekten repräsentieren. Die "dynamische Ontologie" ist also das logische Informationsmodell, das heißt der Vorrat an Objekttypen, Attributbedeutungen, Beziehungstypen usw., die in einer funktionsfähigen Gotham Analyseplattform zum Einsatz kommen.

Die Datenquellen von Hessendata
Die SZ berichtete, dass Daten aus diesen Datenbanken und Quellsystemen in Gotham alias Hessendata integriert werden können:
- drei "Polizeidatenbanken für Kriminalfälle und Fahndungen"
Plausibel wäre, wenn es sich dabei handelt um- die INPOL-Personenfahndung (INPOL/POLAS)
- die INPOL-Sachfahndung (INPOL/POLAS)
- die Datenbank des Fallbearbeitungssystems CRIME, sowie
- Verbindungsdaten aus der Telefonüberwachung (tabellarisch)
- Daten aus ausgelesenen Handys
- BKA-Fernschreiben (EPOST810).
Integration bzw. Mapping der Quelldaten
In enger Abstimmung mit dem Auftraggeber, heißt es weiter im Palantir-Datenblatt, integrieren und mappen unsere [Palantir-]Techniker alle relevanten Daten aus den Quellsystemen und zwar unabhängig von deren Art oder Menge – und überführen sie in ein einziges, logisches Datenmodell.
Es ist nachvollziehbar, dass diese Definitionen für die Integration bzw. das "Mapping", also die Zuweisung von Informationen auf Quellsystemen auf das Palantir-Zielsystem, von Technikern der Firma vorgenommen werden.
Wenn dies nach einem öffentlich nicht bekannten Zeit- und Kostenaufwand geschehen ist, lesen wir in einer Palantir-Produktbeschreibung weiter: Sobald das Datenmodell und die Integration und Zuweisungsinformationen erst einmal erstellt worden sind, "fließen die Daten kontinuierlich aus ihren jeweiligen Quellsystemen in die Palantir-Gotham-Plattform".
Das muss für so manchen Polizeipraktiker wie eine himmlische Verheißung klingen. Einmaliger Aufwand, der sicher Zeit und Geld kostet. Aber wenn das erst einmal investiert worden ist, hat man endlich eine Plattform, auf der relevante Informationen aus vielen verschiedenen Datenquellen zusammengeführt und gemeinsam genutzt werden können. Lassen wir diesen scheinbaren Himmel auf Erden zunächst einmal so stehen. Denn wie zu allen himmlischen Darstellungen gibt es auch hier berechtigte Fragen, die aus Erfahrungen mit der irdischen Welt gespeist werden. Doch dazu mehr im nächsten Teil des Palantir-Dossiers von POLICE-IT.
___
(*) Annette Brückner, die Autorin dieses Artikels, war zwischen 1993 und 2013 Projektleiterin für das polizeiliche Informationssystem POLYGON und in diesem Zusammenhang Designerin von Werkzeugen zur Strukturermittlung, Analyse und Auswertung für den polizeilichen Staatsschutz, sowie für OK-Ermittler und -Analytiker. Sie hat 1995 die Patentschrift für das oben erwähnte generische Speichermodell von POLYGON im Detail geschrieben. Dieses Patent wurde in Deutschland, Österreich, der Schweiz, den Niederlanden und den Vereinigten Staaten erteilt und ist hier einsehbar.
Diesen Artikel finden Sie im Original auf POLICE-IT.
RT Deutsch bemüht sich um ein breites Meinungsspektrum. Gastbeiträge und Meinungsartikel müssen nicht die Sichtweise der Redaktion widerspiegeln.
Fortsetzung: Teil VI – Palantir Gotham alias Hessendata: Dammbruch in der polizeilichen IT
Mehr zum Thema - Zweifelhafte Dienstleistung: Amazon richtet Speicherdienst für US-Geheimdienste ein
Durch die Sperrung von RT zielt die EU darauf ab, eine kritische, nicht prowestliche Informationsquelle zum Schweigen zu bringen. Und dies nicht nur hinsichtlich des Ukraine-Kriegs. Der Zugang zu unserer Website wurde erschwert, mehrere Soziale Medien haben unsere Accounts blockiert. Es liegt nun an uns allen, ob in Deutschland und der EU auch weiterhin ein Journalismus jenseits der Mainstream-Narrative betrieben werden kann. Wenn Euch unsere Artikel gefallen, teilt sie gern überall, wo Ihr aktiv seid. Das ist möglich, denn die EU hat weder unsere Arbeit noch das Lesen und Teilen unserer Artikel verboten. Anmerkung: Allerdings hat Österreich mit der Änderung des "Audiovisuellen Mediendienst-Gesetzes" am 13. April diesbezüglich eine Änderung eingeführt, die möglicherweise auch Privatpersonen betrifft. Deswegen bitten wir Euch bis zur Klärung des Sachverhalts, in Österreich unsere Beiträge vorerst nicht in den Sozialen Medien zu teilen.